
7 Construction and sound bars
Sound bars have the function of leading the vibration of the bridge to all parts of the soundboard. A second function is to separate the soundboard in different parts to optimize the response to specific frequencies.
On sound bars there are decisions to be made on profiles and cross sections. It will be clear that the strength of a sound bar and certainly that of a construction bar has to dominate the strength of the plate it has to strengthen. The resistance against bowing of a right-angled bar is given by the formula:
R = 1/12 * w * h3 (see e.g. ref. 15)
with:
w = width of the bar and
h = height of the cross section
In choosing the shape of the cross section for the bars there are several points to consider:
- The bars should be as light as possible, at least those which are connected to the soundboard and the lower part of the back.
- Construction bars should just be stiff enough to fulfill their strengthening function.
- If you want to increase the strength of a bar increasing the height is much more effective than increasing the width.
- In order to avoid twisting of the bar the height/width ratio should be limited (to ~4).
- The maximum pulling forces will be located in the top of the bars. So the cross section should not be decreased towards the top.
- The bars have to be glued on the plate. If you expect (may be during the lifetime of your instrument) unavoidable strong local forces you should aim for a large gluing surface.
- Depending on the expected bowing forces the height of the bar should vary along the length.
Based on these considerations there is playing room for the choice of the cross section, but only within a narrow scope. In image Construction and sound bars examples are given of cross sections and profiles based on the aforementioned starting points. For the large cross bars the profile indicated as "flattened pawn" should be aimed at, but of course this profile will gradually flatten at the ends.
Image: Construction and sound bars

In the construction of the EB-guitars all sound bars are based on the flattened pawn contour adjusted to the specific function and location of a sound bar. The sound bars have a width of 3.5 to 4 mm and a waist of max. 3 mm. The maximum height of these sounds bars is 5 to 5.5 mm, decreasing at the end of the sound bars. An impression of the application of these sound bars is given in the image Application of the flattened pawn bars. For different luthiers you can find a lot of variations in these numbers. Torres used relative flat bars, about 7 mm wide and 2.5 mm high (7 x 2.5). Later Luthiers tended to apply higher sound bars like Friedrich (~ 5 x 4), Bouchet (~ 6 x 5) or Romanillos (~ 3 x 4). In view of all these considerations it is advised to apply the "flattened pawn" contour for all the large construction bars and for the smaller sound bars as far as possible or as far as you like or are able to.
Image: Application of the flattened pawn bars

Bars from scrap
Many luthiers use scrap material from the top, back or neck for making construction or sound bars. The image below shows in which ways this can be achieved. Starting with a quarter sawn plate, as indicated in this image there are two ways to cut these bars. If we assume that the height of the bar is more than the width we can take the height in the radial direction (bar 1) or in the tangential direction (bar 2).
Image: Bars from scrap
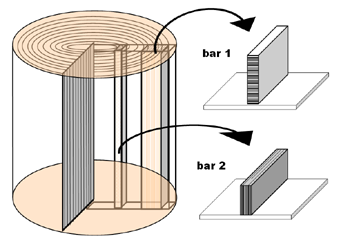
Now the question arises which way is the best: bar 1 or bar 2? Measurements show that it is not possible to measure any difference in elasticity or strength between two identical bars which are coming from the radial or tangential direction. So the pros and cons for using bars of type 1 or type 2, concerning strength and acoustical properties are negligible. Swelling and shrinking due to changing moisture conditions however will be less for bar 2, at least for top wood. This should be the main reason to cut sound bars in the tangential direction, so perpendicular to the plain of the top. For practical reasons an exception can be made for the main traverse bars at the back and above and below the sound hole because their height is more than the thickness of the standard available tops and backs.
